最近搜索
暂无搜索记录
热搜

JAVA
大数据
分布式
Python
人工智能
爬虫
WEB
JavaScript
认证

 0
0 登录
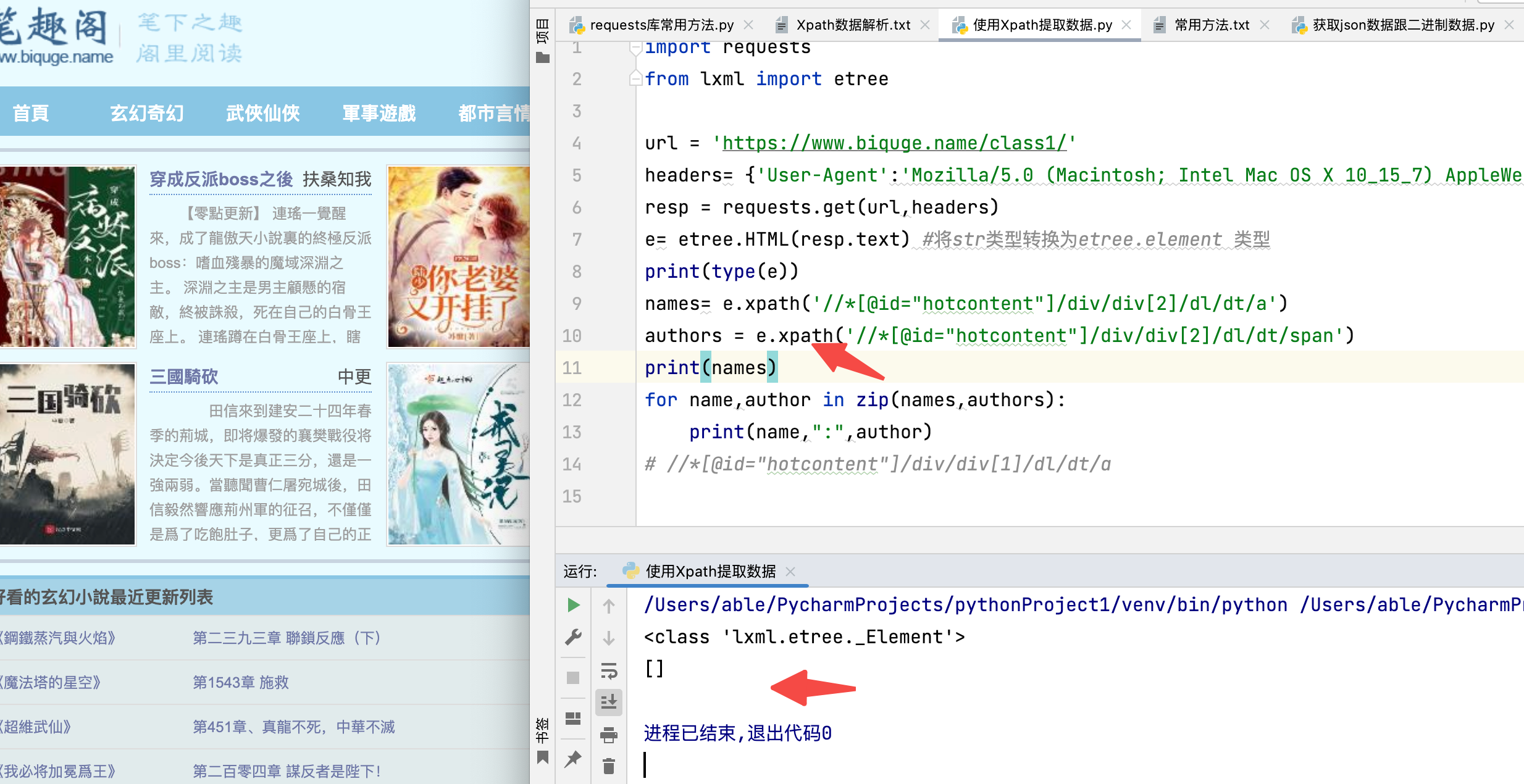
登录import requests
from lxml import etree
url = 'https://www.biquge.name/class1/'
headers= {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}
resp = requests.get(url,headers)
e= etree.HTML(resp.text) #将str类型转换为etree.element 类型
print(type(e))
names= e.xpath('//*[@id="hotcontent"]/div/div[2]/dl/dt/a')
authors = e.xpath('//*[@id="hotcontent"]/div/div[2]/dl/dt/span')
print(names)
for name,author in zip(names,authors):
print(name,":",author)
# //*[@id="hotcontent"]/div/div[1]/dl/dt/a
 1
1
 写回答
写回答




 微信小程序
微信小程序 微信公众号
微信公众号 下载APP
下载APP 品牌/商务合作:4000015096
品牌/商务合作:4000015096



