最近搜索
暂无搜索记录
热搜

JAVA
大数据
分布式
Python
人工智能
爬虫
WEB
JavaScript
认证

 0
0 登录
登录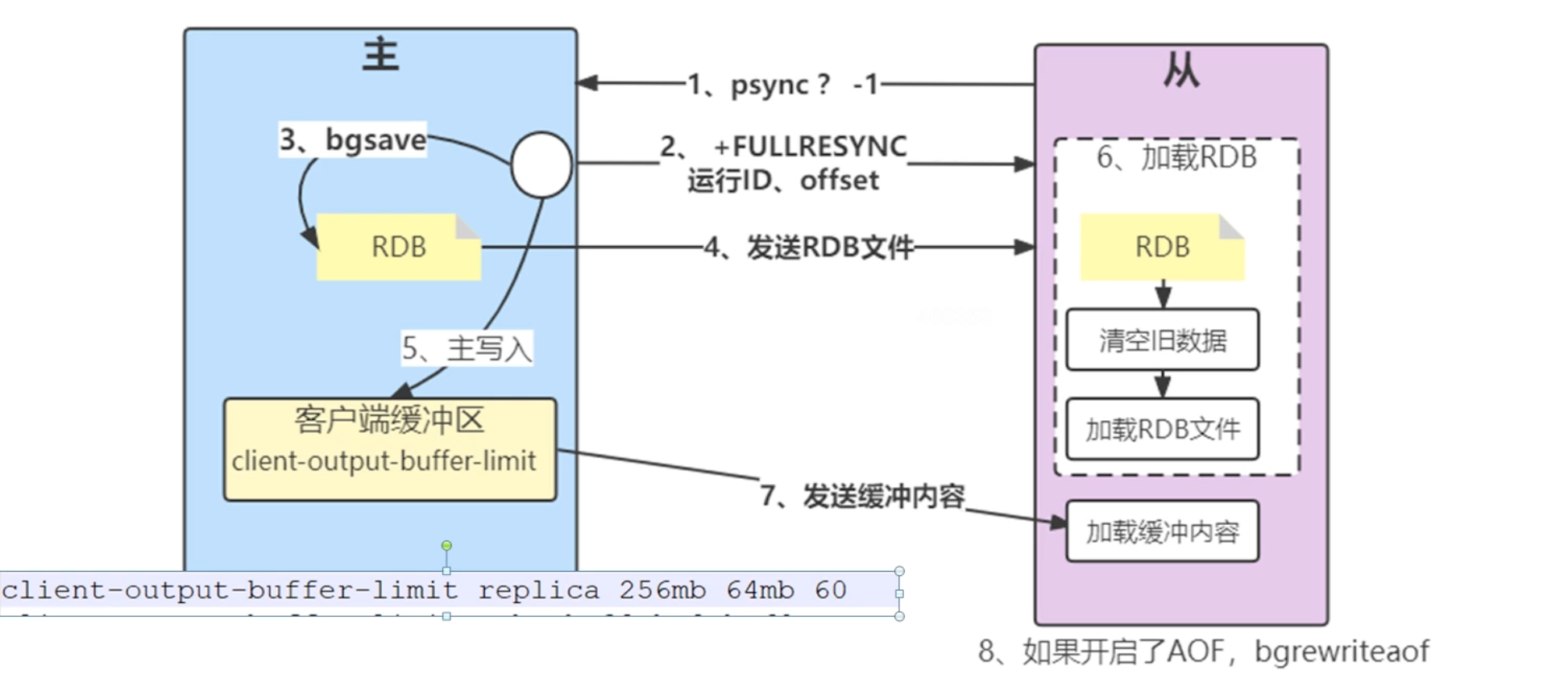

所以,要避免全量复制,只在第一次复制的使用,所以:引入了部分复制
2.在全量复制的图中,第二步的时候发送run_id和offset偏移量,是为了在后面的部分复制的时候使用
有一个复制积压缓冲区的概念
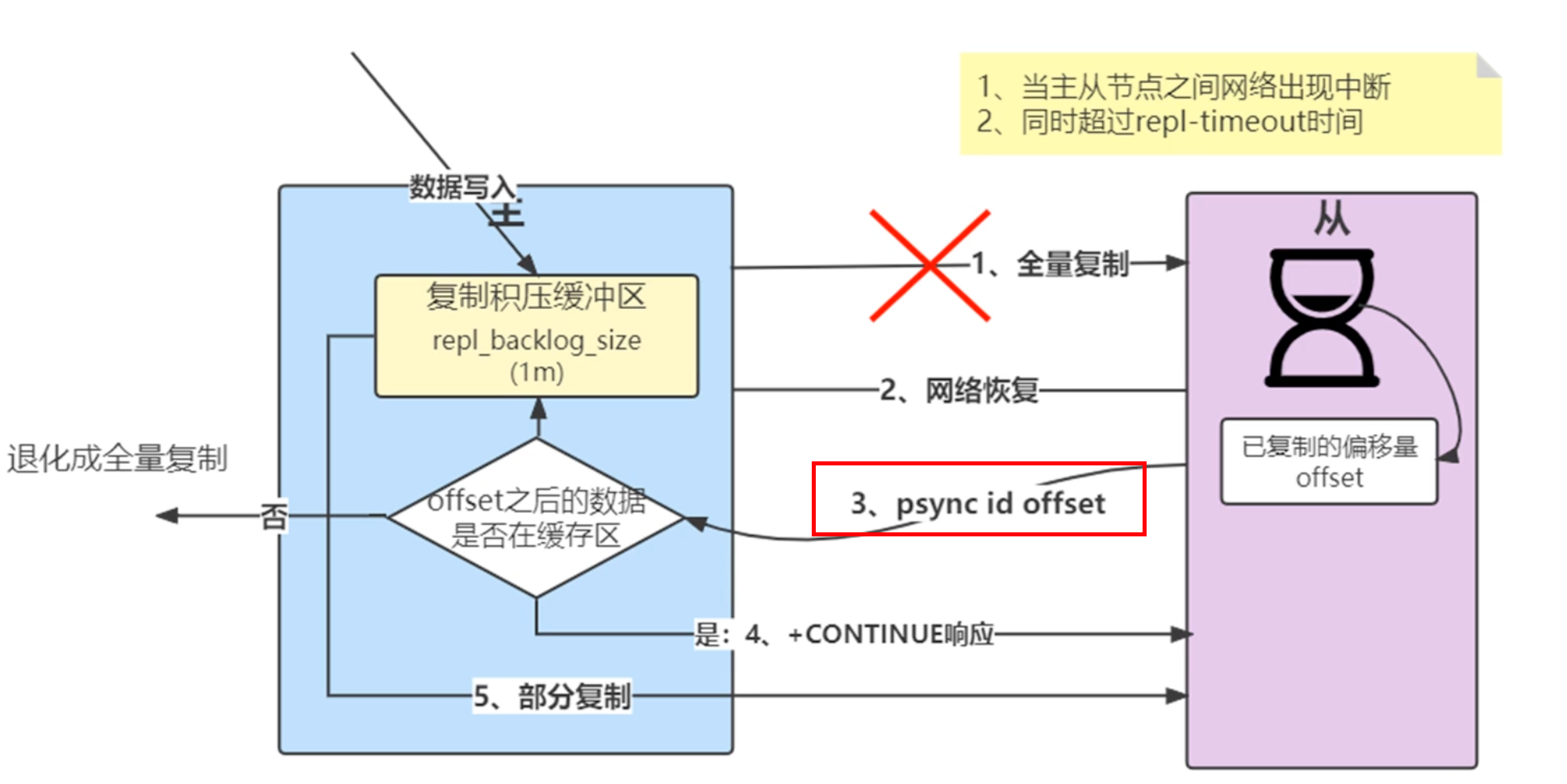
一般都是主节点每隔 10s 对从节点发送ping命令

当我们搭建了主从的时候,当主节点挂了之后,除非我们人工进行slaveof no one命令去更新主节点,否则从节点还是从节点。我们就需要一种机制,来自动监控,或者实现故障的转移
原理:当主节点出现故障的时候,由Redis Sentinel自动完成故障发现和转移,并通知应用方,从而实现高可用
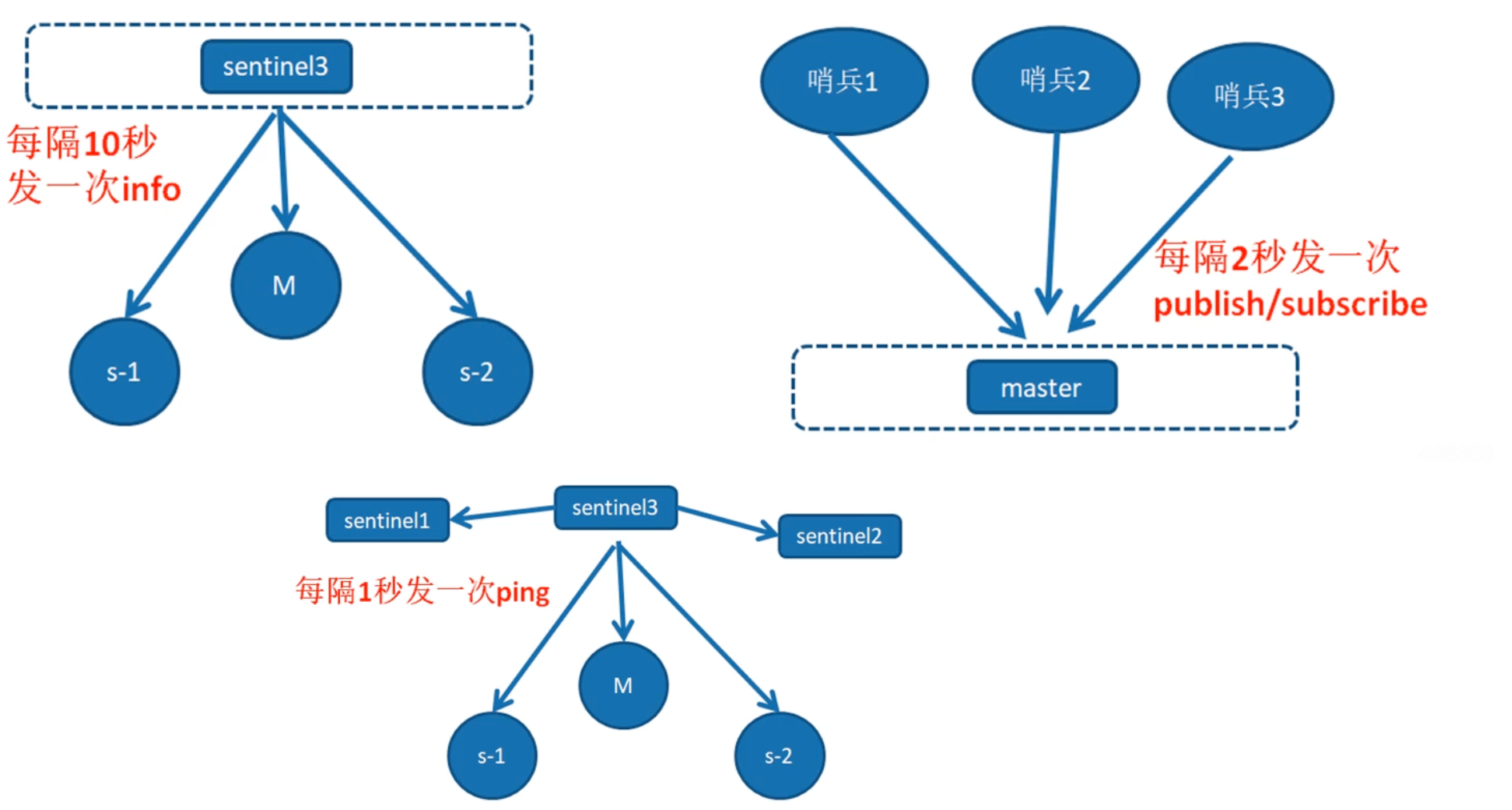
1.每隔10秒 哨兵 向主从节点发送info命令,获取我们节点的信息
2.哨兵和主节点之间的发布订阅模式,同步哨兵之间的数据 和 状态
3.哨兵向所有节点每隔1秒会发送 ping命令
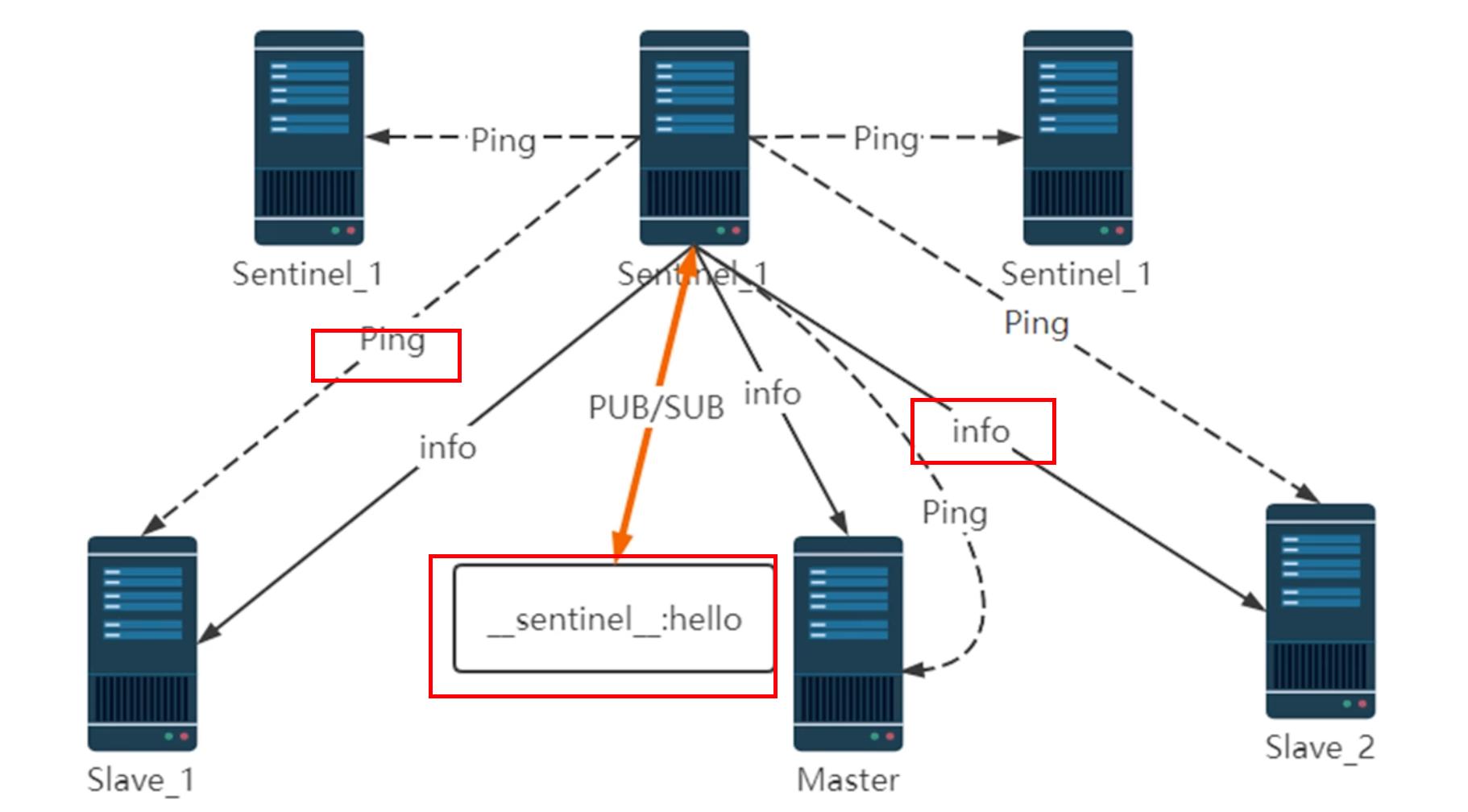
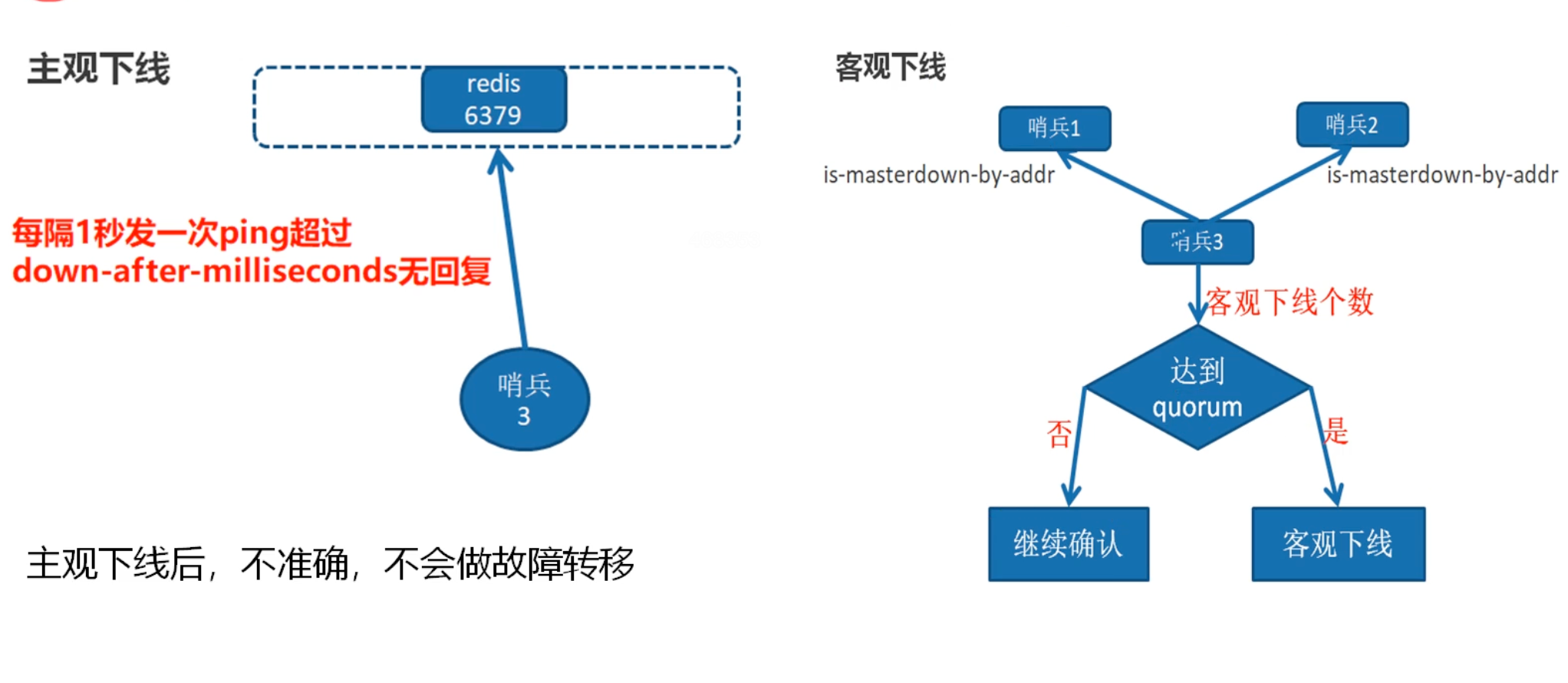
哨兵会定时1s向主节点发送ping命令,当发送命令没有回应的时候,就代表着主观下线。
但是这种模式,也有可能只是那个哨兵和主节点之间的网络问题,所以,这种模式不会实现故障的转移
我会循环所有哨兵的意见,当下线个数超过配置文件中的值时,就认为是客观下线了,否则就继续确认

当哨兵3先发现节点主观下线之后,就会询问其他哨兵的意见,如果都统一之后,那么哨兵3就会成为领导着,负责故障的转移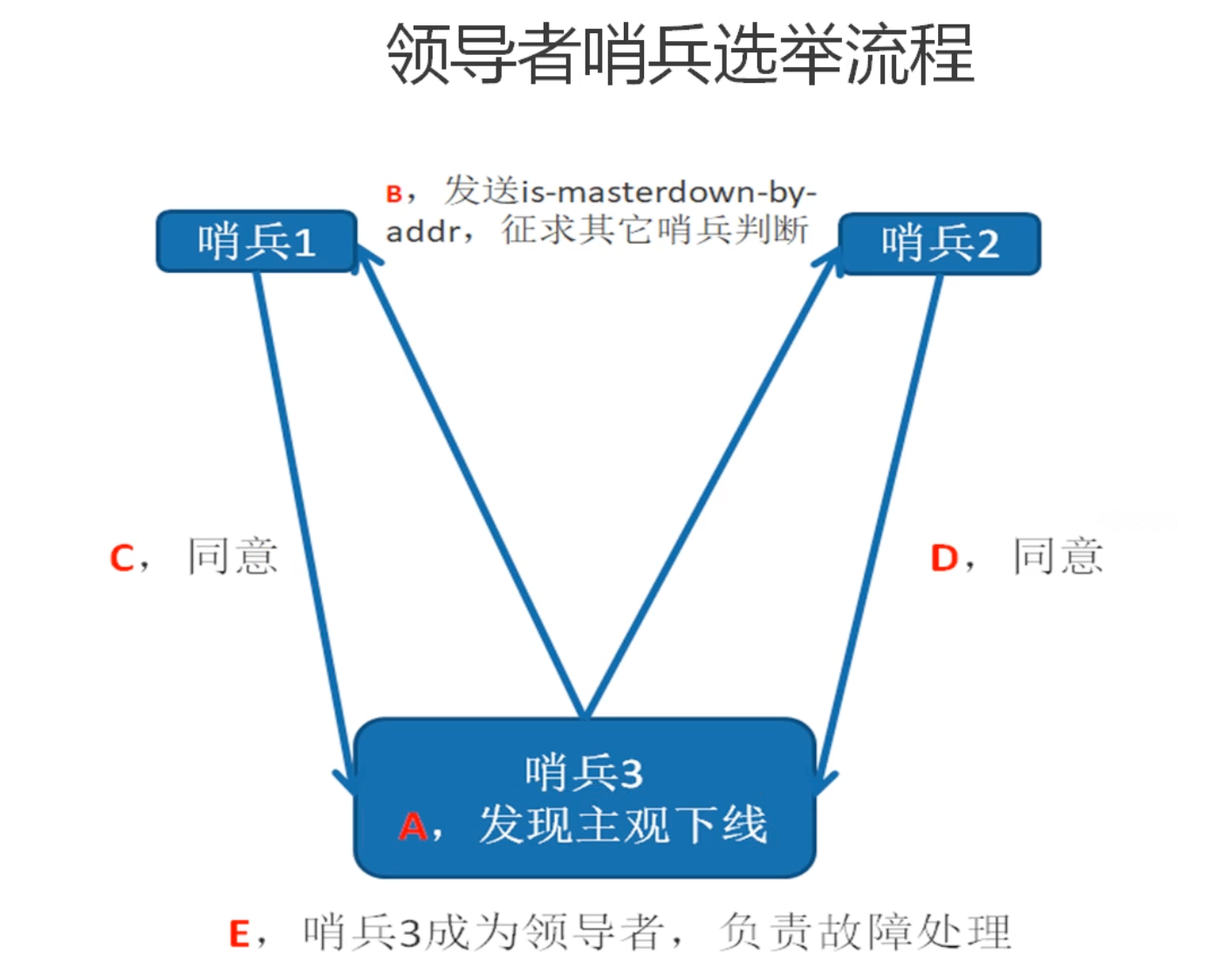
java实现raft算法的案例,蚂蚁金服

第一步是:从 从节点列表中 先选择出来 一个从节点
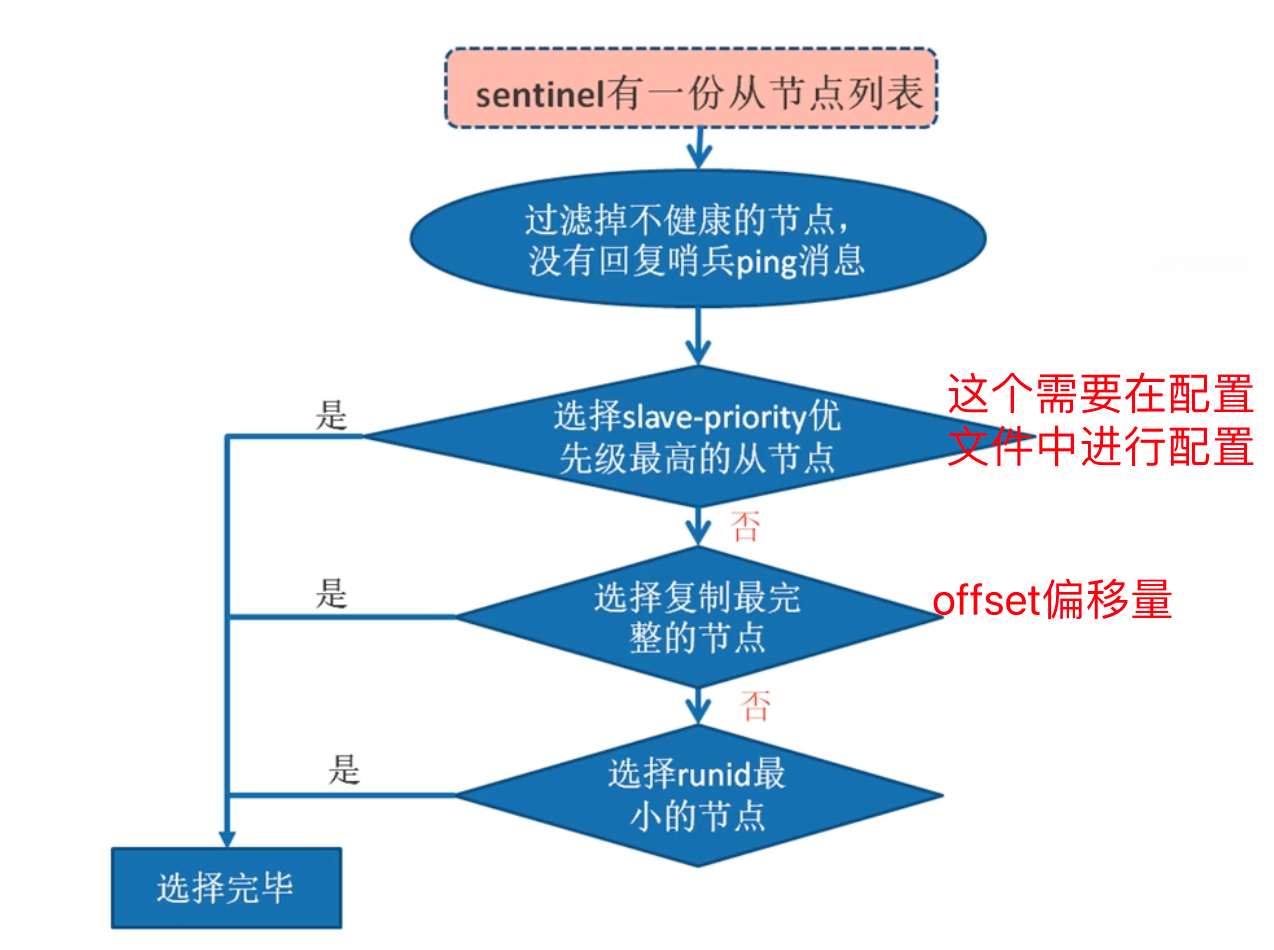
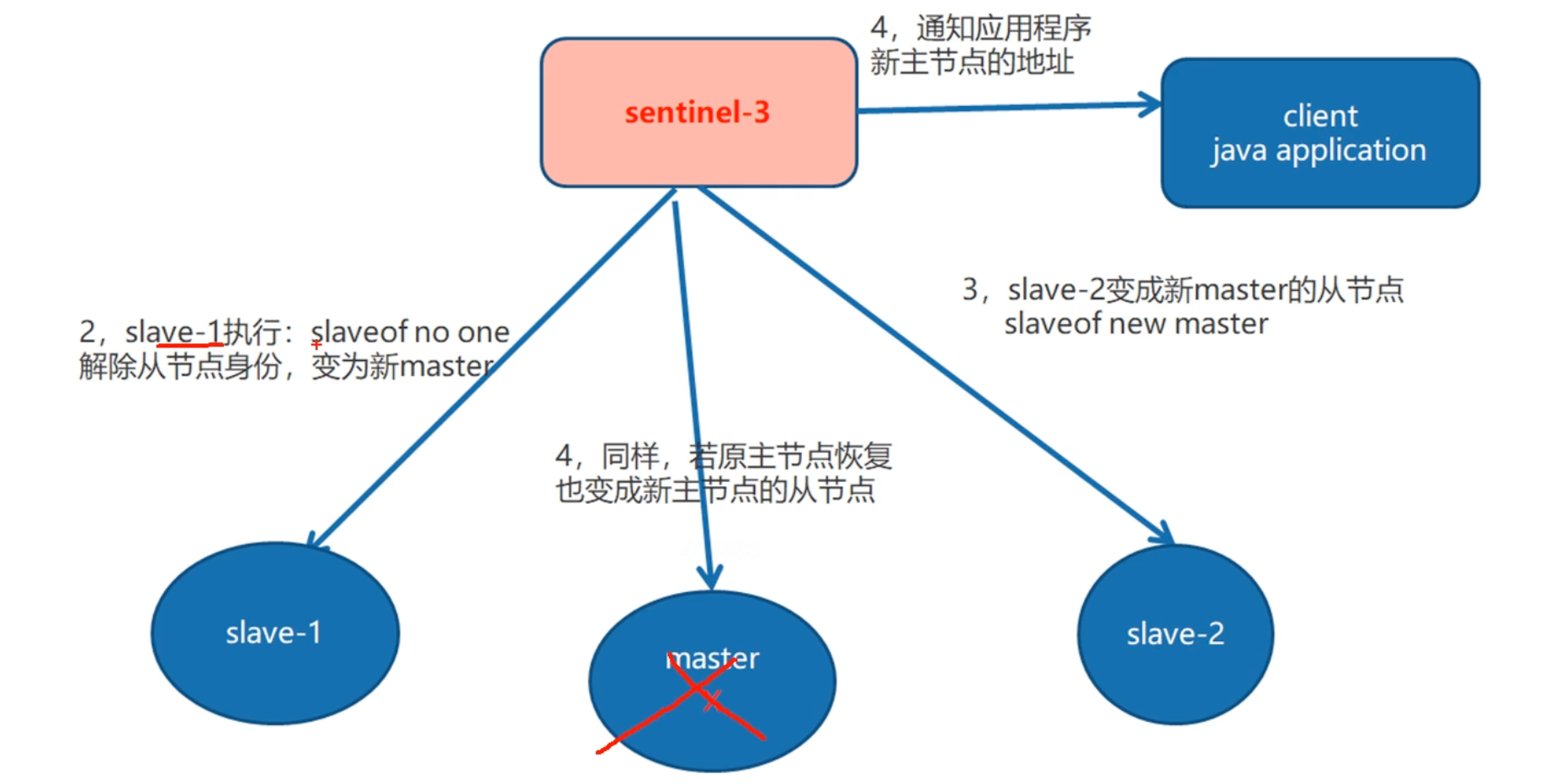
1.选举出来之后,还的完成 将这个节点修改为 主节点,
2.将其他的节点更新到这个主节点之下,
3.原先的主节点在恢复后,也的做为从节点
4.哨兵客户端通知应用程序更新后的新主节点的地址
这是为了充分利用 从节点的资源的,使从节点也可以写

 程序猿一号
程序猿一号 



 微信小程序
微信小程序 微信公众号
微信公众号 下载APP
下载APP 品牌/商务合作:4000015096
品牌/商务合作:4000015096 47
47 0
0

